Customized Parallel
Computing (CPC) group
This is the home page of the CPC research group of Tampere University. The group's name in Finnish is Räätälöity rinnakkaislaskenta. CPC's main research focus is on design and programming methodologies of customized parallel computing platforms and real time implementations of challenging algorithms.
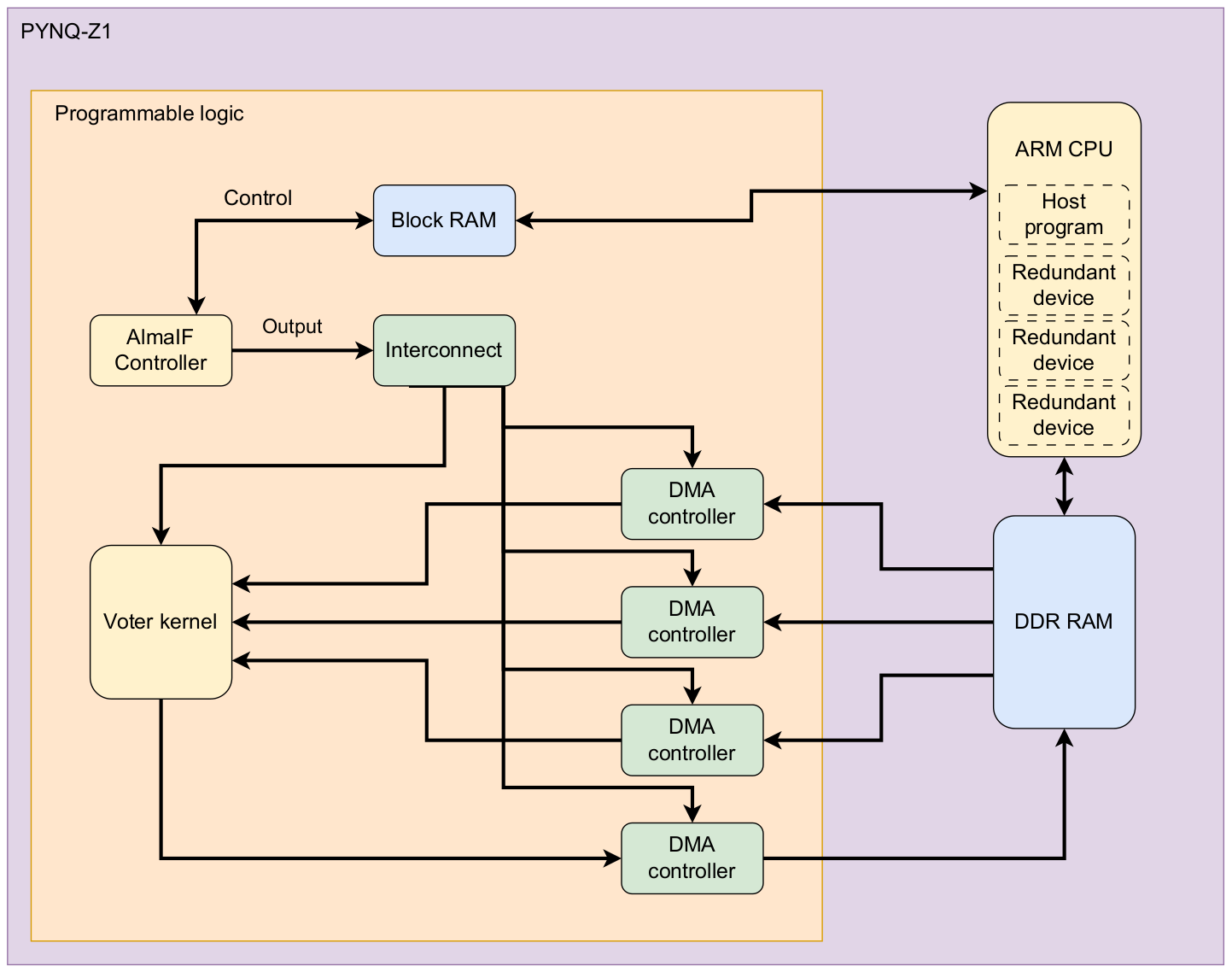
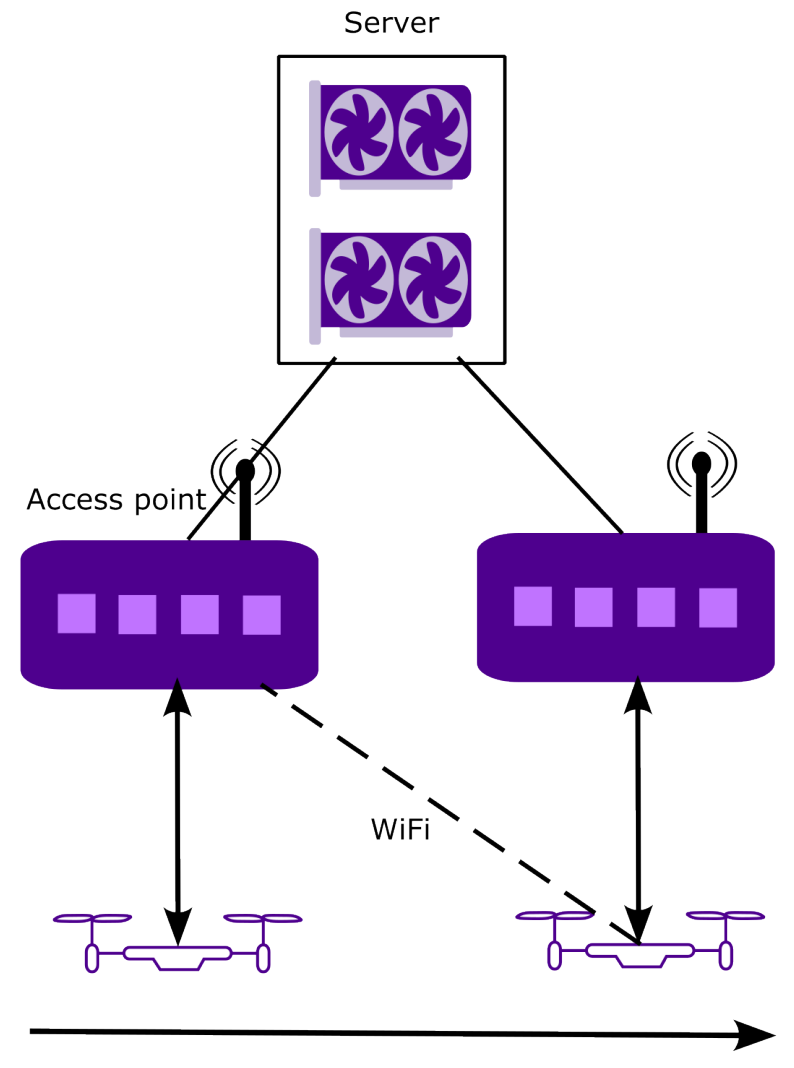
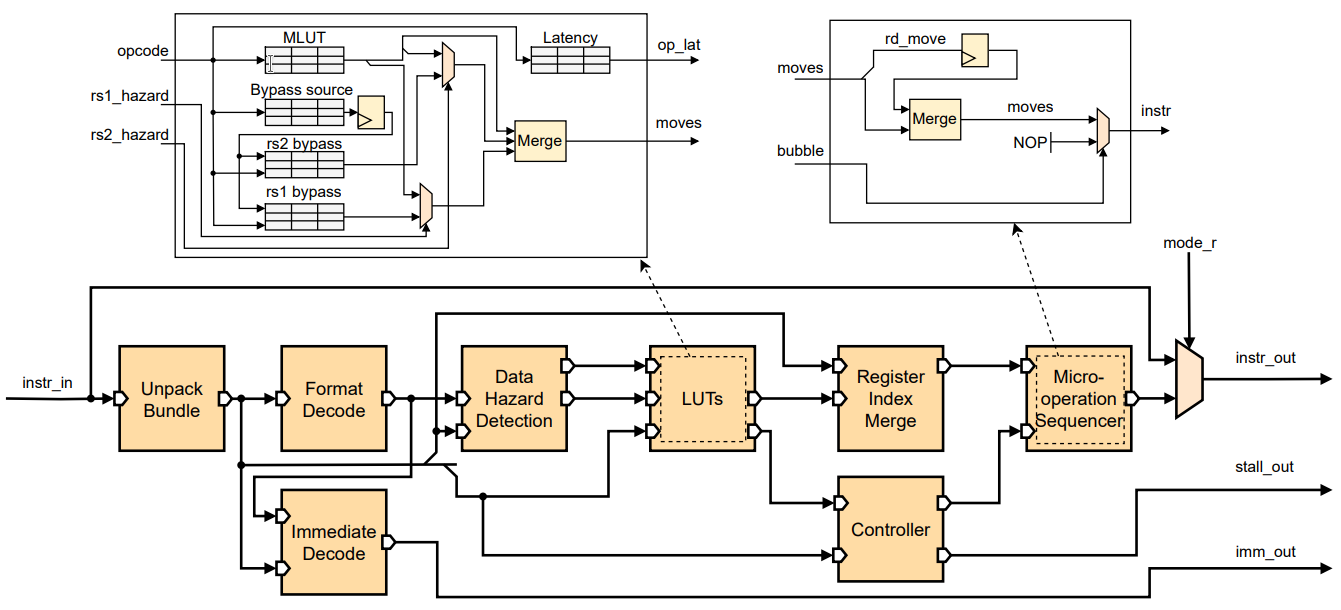
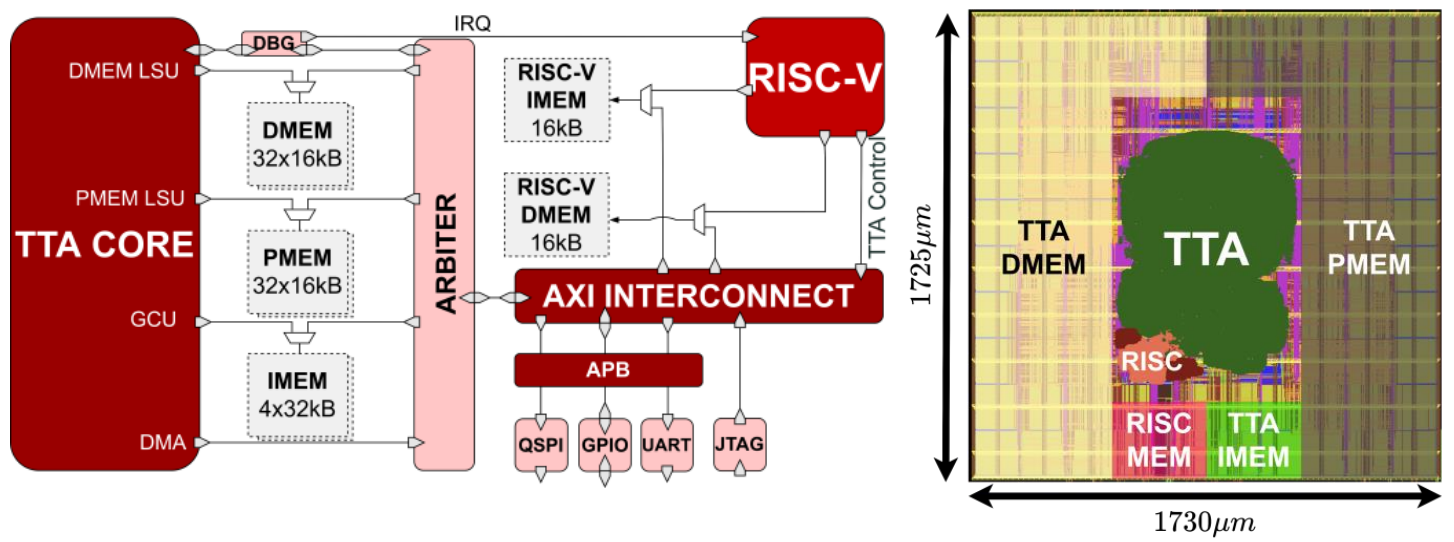
In addition to publications and theses listed here as academic contributions, CPC has also made major open source contributions in the field of portable and customized heterogeneous computing: The group has created OpenASIP and Portable Computing Language (pocl) which are being used widely as research platforms and even for product use cases. CPC also created the prototype HIPCL tool which evolved into chipStar, a portable CUDA/HIP implementation using open standards.
An algorithm domain with extreme computational demands that CPC has been very interested in the past years is real time ray tracing. A separate focus group was formed for finding algorithmic, parallel/heterogeneous implementation and custom hardware solutions for its challenges in 2015. The group's web pages are here.








Social Media
Follow the CPC group on Twitter/X: https://twitter.com/CustomParComp